Scaling Prometheus: From Single Node to Enterprise-Grade Observability


Prometheus is an open-source monitoring solution that provides a streamlined way to store metrics data, query metrics using PromQL, and set up alerting. It has become the de-facto standard for monitoring infrastructure and applications.
- Easy to setup: Prometheus is straightforward to deploy - simply run a single
prometheusbinary and you're ready to ingest and query metrics. It uses a single-node setup rather than a clustered architecture, making it simple to deploy but introducing scalability limitations that we'll discuss later. - Service Discovery and Pull-based model: The Prometheus server pulls metrics from your services through service discovery. This simplifies deployment since services don't need to know about the central Prometheus setup. Each application service only needs to expose its metrics over an HTTP server in the Prometheus text exposition format, and Prometheus will periodically pull these metrics based on the configured
scrape_interval. - Storage Engine: Prometheus stores time series data in memory and on local disk in an efficient custom format.
- Powerful Queries: Prometheus allows querying time series data via PromQL, a language that allows slicing and dicing of time series data over the labels and time ranges.
- Alerting: Prometheus supports alerting on the time series data with alert rules specified in PromQL, and notifications handled by Alertmanager.
- Third-party Integrations: Prometheus can easily collect data from third-party tools via exporters and also serve as a data-source for dashboarding tools such as Grafana.
Prometheus is a great starting point if you are just getting started with Observability. However, the reasons which make it easy to set up and operate at low scale are also the reasons why it can become challenging to operate Prometheus at scale. To understand the limitations of Prometheus, we need to build a good mental model of how it stores data and what affects its scalability.
Understanding Time Series: The Building Blocks of Prometheus
Prometheus fundamentally stores all data as time series: streams of timestamped values belonging to the same metric and the same set of labeled dimensions.
For example, a time series with the metric name api_http_requests_total and the labels method="POST" and handler="/messages" could be written like this:
api_http_requests_total{method="POST", handler="/messages"}
For each time series, Prometheus stores a (timestamp, value) for the associated metric and set of labels at each scrape_interval. By default, Prometheus stores all time series in memory for two hours and flushes them to local on-disk storage at the end of the two-hour-interval.
Understanding Prometheus's data model helps us see that its memory usage directly correlates with the number of active time series it scrapes. This leads us to the cardinality explosion problem. In the above example, if method can contain four possible values - GET, PUT, POST, and DELETE, and handler can contain ten possible values, the total cardinality of api_http_requests_total becomes 40 (4*10). If you then add a status label with two possible values (success or failure), the total cardinality increases to 80 (4*10*2). High cardinality metrics can easily occur when you have dynamic labels or when the cross-product of multiple label cardinalities becomes large. Since the number of time series is determined by unique label combinations across all metrics, label cardinality directly impacts the Prometheus server's memory usage.
This highlights a key limitation of Prometheus: The memory required by a Prometheus server directly correlates with both the number of time series it scrapes and their associated scrape intervals. As the number of time series grows, vertical scaling of the Prometheus server becomes necessary.
The Storage Challenge: Managing Data on Disk
As mentioned earlier, Prometheus stores data older than 2 hours (by default) to local on-disk storage. Prometheus will further run compaction on the data sitting on disk to merge them into larger blocks. The reliance on local on-disk storage impacts reliability and durability of Prometheus setup as noted in Prometheus's Storage documentation:
Note that a limitation of local storage is that it is not clustered or replicated. Thus, it is not arbitrarily scalable or durable in the face of drive or node outages and should be managed like any other single node database.
In addition to scalability limitation of on-disk storage, it also adds additional operational overhead:
- The local storage needs to be backed up with snapshots to be able to recover from disk failures/operational errors.
- It needs to be capacity planned periodically to account for increase in the number of time series/infrastructure growth.
Query Execution: Walking the Performance Tightrope
PromQL allows slicing and dicing of data across various time ranges and labels. It allows complex queries which may require scanning through a lot of data. Given the single-process architecture of Prometheus, heavy queries may require excessive CPU or memory, causing OOM on the prometheus server or making it slow for other queries.
Beyond Single-Node: Strategies for Scaling Prometheus
Having examined the key limitations of single-node Prometheus setups, let's explore various solutions for scaling Prometheus.
Divide and Conquer: Functional Sharding
To address Prometheus's limitations in handling large numbers of time series, one approach is to shard the time series data across multiple Prometheus servers. This can be achieved by dividing the data based on teams, clusters, service groups, or other logical boundaries. While this allows running multiple Prometheus servers with each handling its own subset of time series data, it introduces new challenges.
The main drawback is the loss of centralized query capability across all metrics. Users need to know which metrics are stored on which servers and query them accordingly. Additionally, this approach prevents joining data from different metrics at query time if they're stored on different servers.
Building Bridges: Federation and Global Views
Prometheus's Federation feature enables one Prometheus server to scrape selected time series from another. This partially addresses the central visibility challenge by allowing a central Prometheus server to pull aggregated metrics from functionally sharded servers, providing an aggregate global view.
For example, you might set up multiple per-datacenter/region Prometheus servers that collect detailed data (instance-level drill-down), alongside global Prometheus servers that collect and store only aggregated data (job-level drill-down) from those local servers. This architecture provides both aggregate global views and detailed local views.
However, this approach still doesn't enable querying across all raw data.
Breaking Free: Remote Storage Solutions
Since neither Functional Sharding nor Federation fully solves central visibility or addresses data durability concerns, let's explore solutions that leverage remote storage.
Thanos: Global Querying with Object Storage
Thanos is an open-source project that extends Prometheus with long-term storage capabilities. Built on top of Prometheus, Thanos enables object storage as a long-term storage solution for Prometheus data. It offers three key benefits:
- A global query view across all Prometheus servers
- Durable long-term storage through object storage
- Deduplication of data from replicated Prometheus servers
Thanos maintains the same data format on object storage as Prometheus uses for its on-disk storage. By enabling unlimited storage, Thanos allows for unlimited data retention. While it solves the central visibility problem by allowing unified querying across multiple Prometheus servers and object storage, Thanos still depends on individual Prometheus servers for data collection and recent data serving. This means you'll still need to handle capacity planning and functional sharding of Prometheus servers, along with their associated operational overhead.
Thanos includes a query frontend that can cache results and split long time range queries into smaller ones. While this improves query performance against object storage, heavy queries (especially those spanning long time ranges) may still experience slower performance.
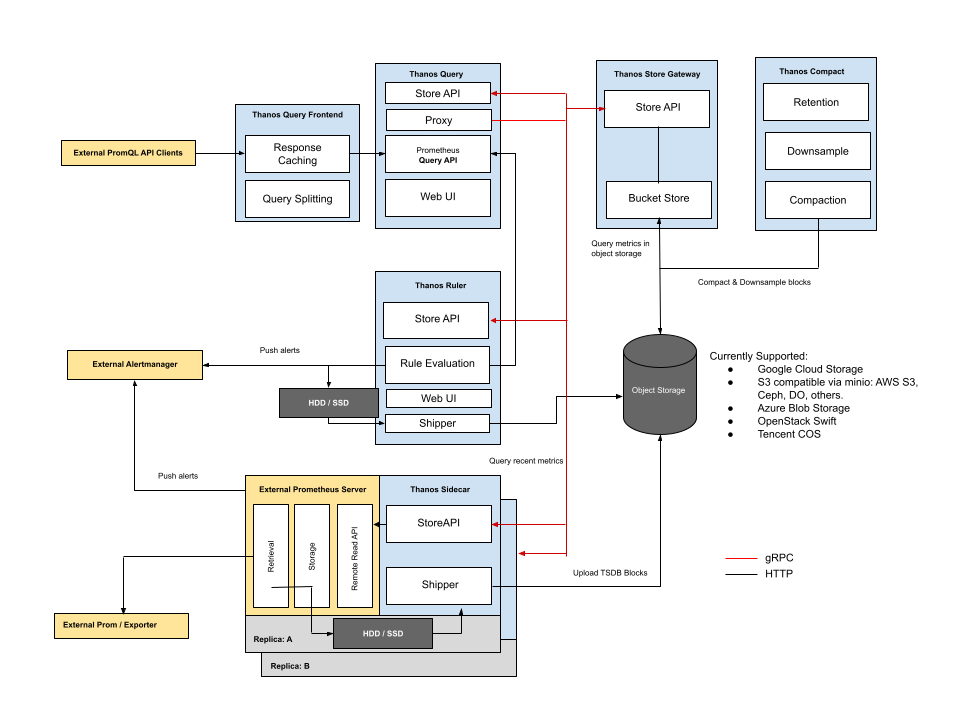
Source: https://thanos.io/tip/thanos/quick-tutorial.md/
Cortex: Multi-tenant Scalability
Cortex provides a horizontally scalable, multi-tenant, long-term storage solution for Prometheus. It accepts metrics data via the Prometheus remote-write protocol and stores them in object storage (similar to Thanos). Unlike Thanos, Cortex eliminates the need for Prometheus servers to serve recent data since all data is ingested directly into Cortex. It also adds multi-tenancy features and allows for configuring various quotas and limits per tenant. However, like Thanos, query performance for long-range queries may be slower due to the need to fetch data from object storage.
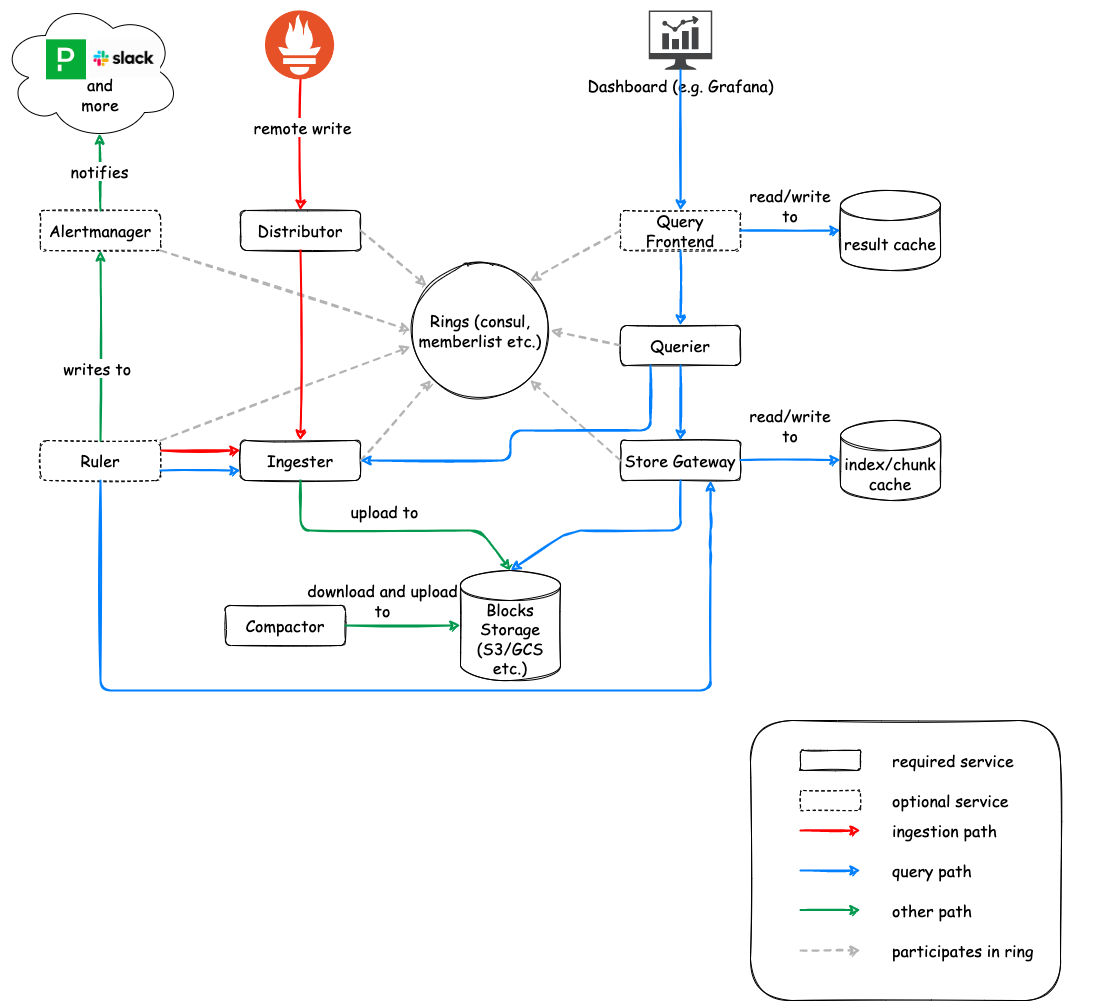
Source: https://cortexmetrics.io/docs/architecture/
Grafana Mimir: Enterprise-Ready Cortex Evolution
Grafana Mimir has a similar architecture as that of Cortex and was started out as a fork of Cortex due to licensing issues. Grafana uses Mimir architecture in their Grafana Cloud offering.
Victoria Metrics: High Performance at Scale
Victoria Metrics offers a high-performance, open-source time series database and monitoring solution that can serve as Prometheus remote storage. It differs from Thanos and Cortex in two key ways:
- It uses disk storage rather than object storage
- It employs its own optimized columnar file format instead of the Prometheus format
Compared to Cortex, Victoria Metrics offers simpler setup and operation due to its streamlined architecture.
Making the Right Choice: Solution Comparison
We've explored how Prometheus excels as an easy-to-deploy metrics monitoring system at small scale, while examining its limitations at larger scales. We've also reviewed several open-source alternatives that address these limitations. Here's a summary of the solutions discussed:
| Dimension | Prometheus Federation |
Thanos | Cortex / Mimir |
Victoria Metrics |
|---|---|---|---|---|
| Functional Sharding | ✅ | ✅ | Not Needed | Not Needed |
| Global Query View | 🟠 | ✅ | ✅ | ✅ |
| Data Durability | 🔴 | 🟠 | ✅ | 🟠 |
| Query performance | 🟠 | 🟠 | 🟠 | ✅ |
| Unlimited storage | 🔴 | ✅ | ✅ | 🔴 |
| Operational Overhead | 🟠 | 🟠 | 🟠 | 🟠 |
| High Cardinality | 🔴 | 🔴 | ✅ | ✅ |
In the next part of this blog series, we will look at how Oodle solves the scalability issues of Prometheus in detail. Stay tuned!