How Lookout Migrated to Oodle After 8 Years on Datadog


After 8 years on Datadog, Lookout's observability bill was growing faster than the value they got from it. Here's how they migrated 3,500 nodes, 300+ dashboards, and 2,000 alerts to Oodle in 6 weeks — without the usual migration horror story.
"We'd been on Datadog for many years with a sizable contract for several thousand nodes. We had amazing pricing compared to market benchmarks, an 8-year-old rate we managed to negotiate year after year, but it was still extremely expensive."
— Nagendra Swamy, VP, Lookout

If any of these sound familiar, this migration story is for you:
- Your Datadog bill makes finance ask questions every quarter
- You've built years of workflows around a tool and feel locked in
- You've been asked to "evaluate alternatives" but don't know where to start
- You've tried migrating observability vendors before and got burned
- You want to understand the real effort involved
Lookout is a cybersecurity company protecting over 2,000 enterprises and 230M mobile devices worldwide. They run infrastructure across AWS and GCP with several thousand nodes. Here's how they moved off an expensive Datadog contract and migrated 3,500 nodes to Oodle in 6 weeks.
Why Lookout Considered Switching
Great Discounts, Still a Big Bill
Datadog is an excellent product. Lookout had been customers for 8 years with no complaints about the platform itself.
"We'd been on Datadog for many years with a sizable contract for several thousand nodes. We had amazing pricing compared to market benchmarks — an 8-year-old rate we managed to negotiate year after year — but it was still extremely expensive."
— Francisco J. Reyes, Lookout
Sound familiar? Many long-term Datadog customers face this exact tension. You can have great discounts compared to new customers and still pay a bill that's hard to justify.
The Accumulated Complexity Problem
Eight years of usage creates more than dashboards and alerts. It builds up complexity: Datadog-specific tooling, architecture to manage costs, configurations nobody fully understands anymore. Think of it like a house you've lived in for a decade: you've renovated the kitchen three times, the wiring is a mess, and there's a closet nobody opens.
"We'd had the contract for so long, we had a lot of stuff in there. A lot of unnecessary stuff. It was a massive undertaking to streamline and right-size."
— Francisco J. Reyes, Lookout
Two issues compounded on each other:
- Cost vs. Value Divergence: The bill was huge despite "amazing" rates, and the value wasn't proportional
- Platform Complexity: Years of accumulated configurations made it hard to optimize or reduce spend
The Lock-in Reality
Here's the most frustrating part. Traditional cost optimization wasn't an option.
"We couldn't reduce costs because we couldn't reduce volume, and we were already at an amazing rate, so further discounts weren't possible. Contractually, we were locked into spending far more than we wanted for this level of visibility."
— Francisco J. Reyes, Lookout
When you're already at the floor of your negotiated pricing, the only paths forward are: accept the cost, reduce visibility, or find an alternative.
Lookout chose to explore alternatives.
What Lookout Was Looking For
The team wasn't just looking for "cheaper." Before spending time on a PoC, they needed confidence in three areas: cost, effort, and long-term platform direction.
Predictable Economics
Every vendor claims to be cheaper than Datadog. That's table stakes. Lookout needed to verify the details:
What they asked:
- What's your pricing model? Per host? Per GB? Per unique time series?
- How do you price custom metrics? (This is where costs tend to explode.)
- What happens at renewal? Will you lock in rates?
- Can you handle our full production volume during the PoC without data caps?
What they watched out for:
- Vendors cheapest for only one signal (logs, metrics, or traces)
- First-contract discounts that spike at renewal
- Data caps during PoC that prevent real validation
- Whether the quoted cost includes infrastructure, or only subscription fees, especially for BYOC vendors where compute is billed separately
What they found with Oodle:
- Transparent pricing with no hidden multipliers
- No separate pricing for infrastructure metrics vs. custom metrics (a major cost driver in Datadog)
- No user-based pricing
- No separate ingestion vs. query charges
- No additional costs for alerts
- No PoC data limits; the recommendation was to send full production workload
The result is pricing that scales with your infrastructure, not against it.
Low Migration Risk
This is where most migrations fail before they start. Lookout needed clear answers:
Code changes:
- Do we need to modify application code?
- Do we need to change how metrics, logs, or traces are emitted?
Infrastructure changes:
- Do we need to deploy new collectors (e.g., OpenTelemetry)?
- What compute resources will this require?
Migration ownership:
- Who migrates dashboards and alerts: vendor or customer?
- Who handles the edge cases?
What Lookout experienced:
- Zero code changes: Data ingested directly from existing Datadog agents
- Minimal config changes: Under 10 lines added to Datadog agent config for dual-shipping
- Vendor-owned migration: Oodle migrated all dashboards and alerts; Lookout focused on verification
- Direct engineering support: You work with Oodle engineers, not a customer success relay
Most alternative vendors require you to forward data through an OpenTelemetry Collector first. Translating DogStatsD through an OTel Collector is resource-intensive, adding compute costs and complexity just to run an evaluation.
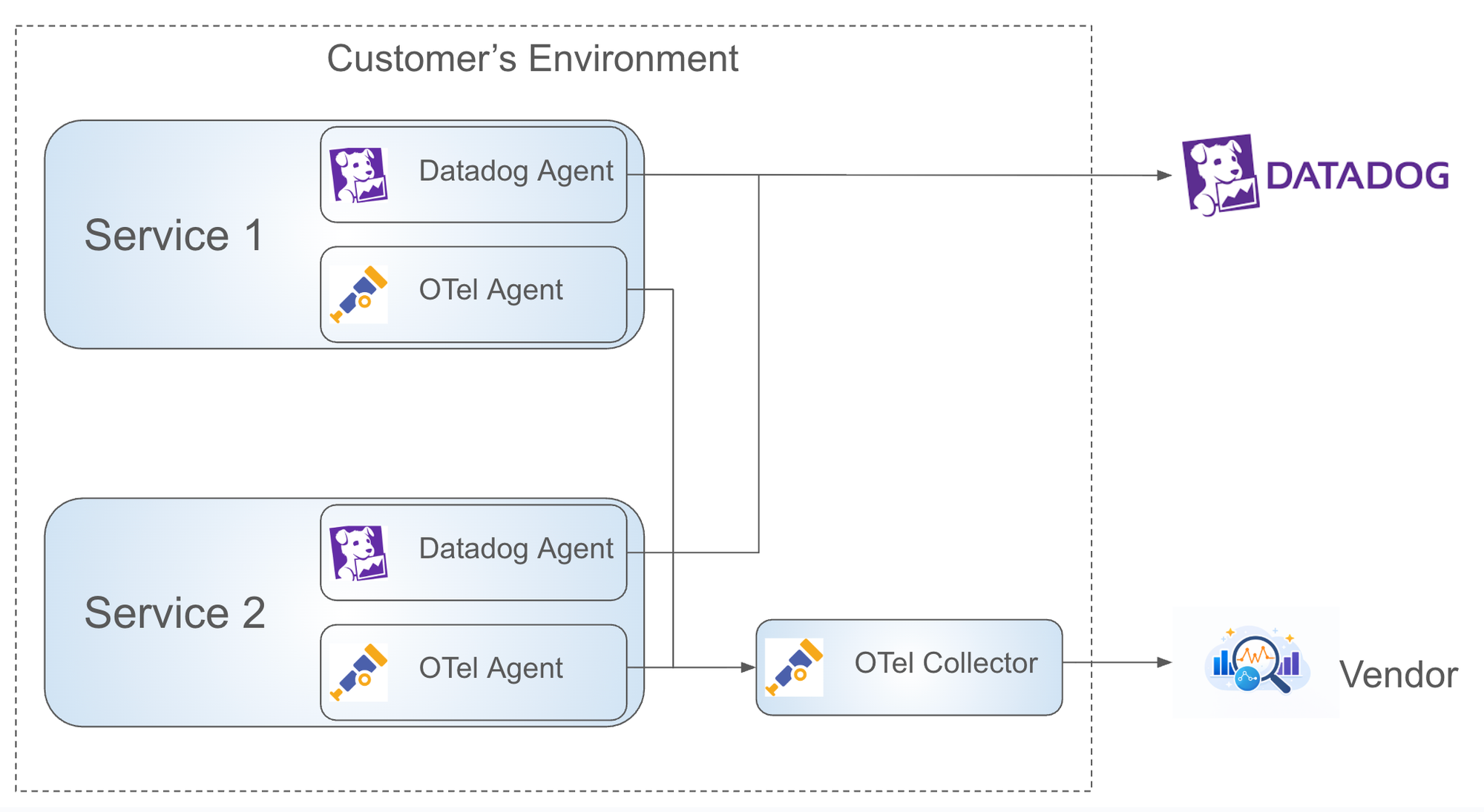
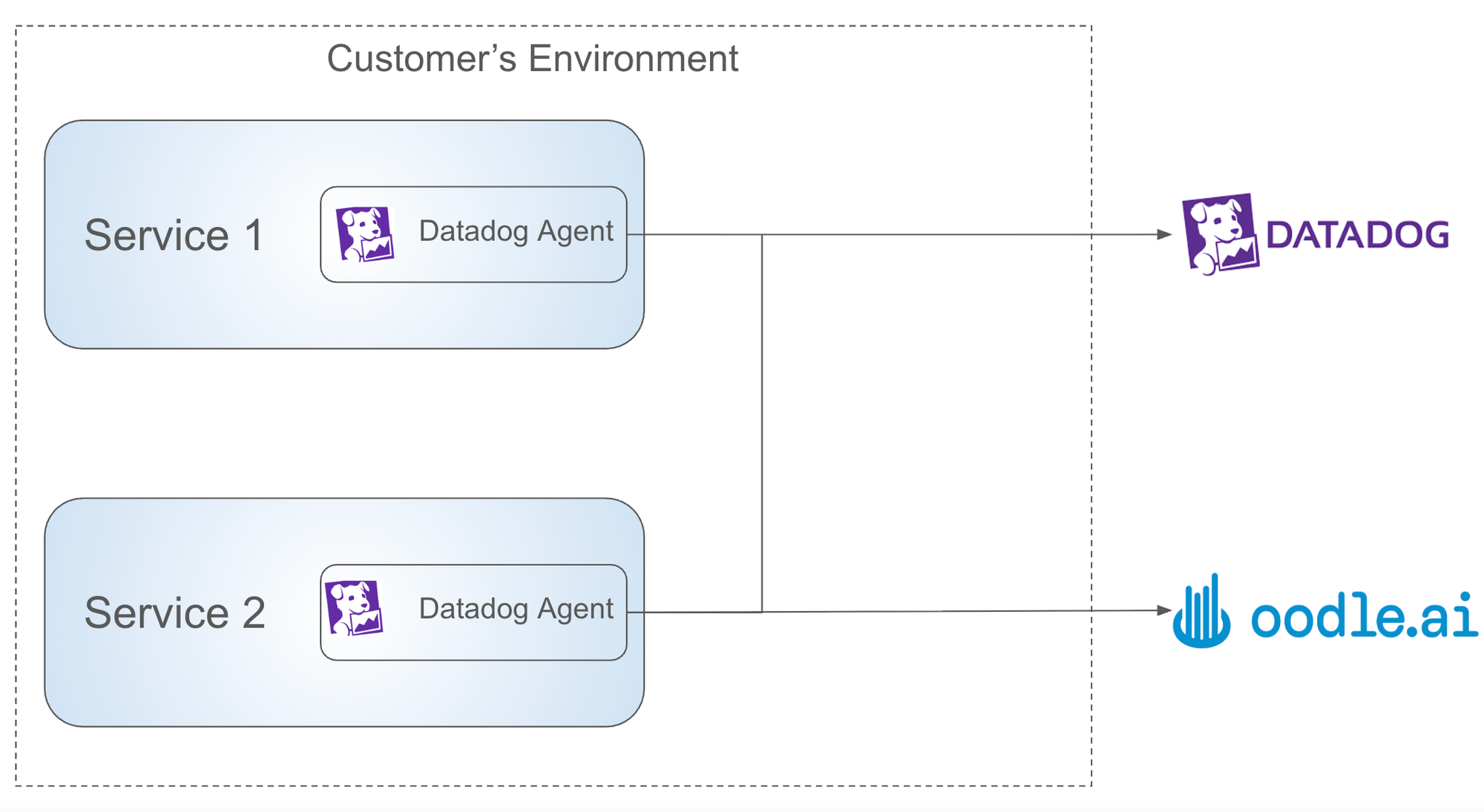
"The biggest surprise was that we could leverage the Datadog client. That made switching much simpler. If we'd had to roll out a whole new client and integration, I don't think we would have done it in the time frame we had."
— Beatrice Gelman, Senior Manager, Lookout
A Modern AI-Native Platform
Beyond cost and risk, Lookout wanted a platform built for the next few years, one that supports their plans to expand AI usage across observability workflows.
Oodle's AI lets teams ask questions in plain English instead of writing queries. It helps validate hypotheses during incidents and is available across the UI, Slack, and developer tools like Cursor and Claude Code. For Lookout, It was a signal that the platform was heading in the same direction as their engineering org.
The PoC Journey
A good PoC does more than check boxes. It builds enough confidence that your teams trust the data and can work in the new system day to day. Lookout focused on three areas during their ~3-week PoC.
Setting Up Data Ingestion
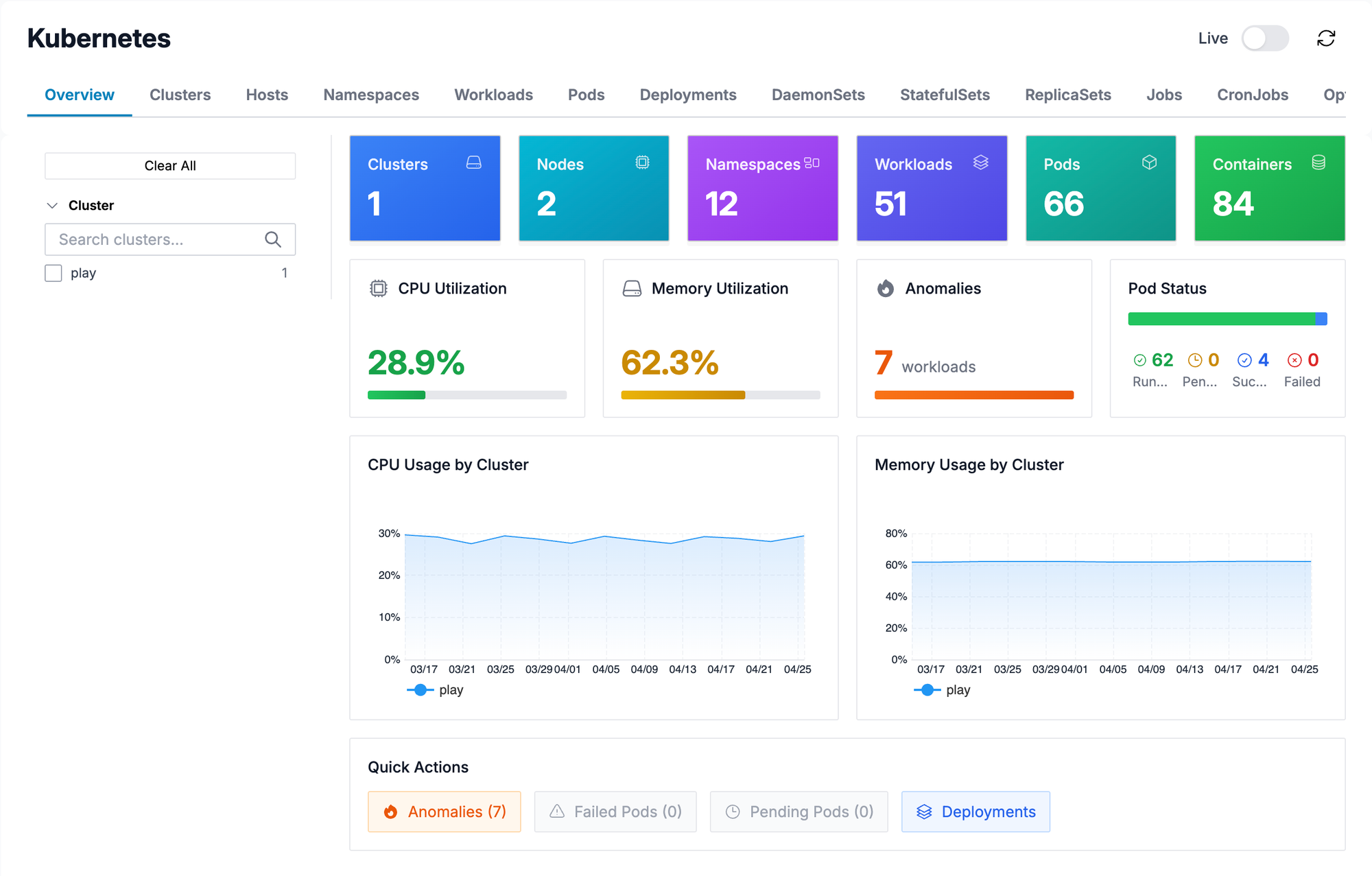
Lookout runs services across GCP and AWS. They needed to confirm that all telemetry signals from both clouds ingested correctly, that Oodle's out-of-the-box dashboards matched Datadog's, and that metrics were automatically tagged with cloud resource tags.
Data Enrichment: The Hidden Complexity
Building trust is hard. Your team needs to believe that the numbers in the new platform match what they relied on before. A big part of that trust starts with data enrichment.
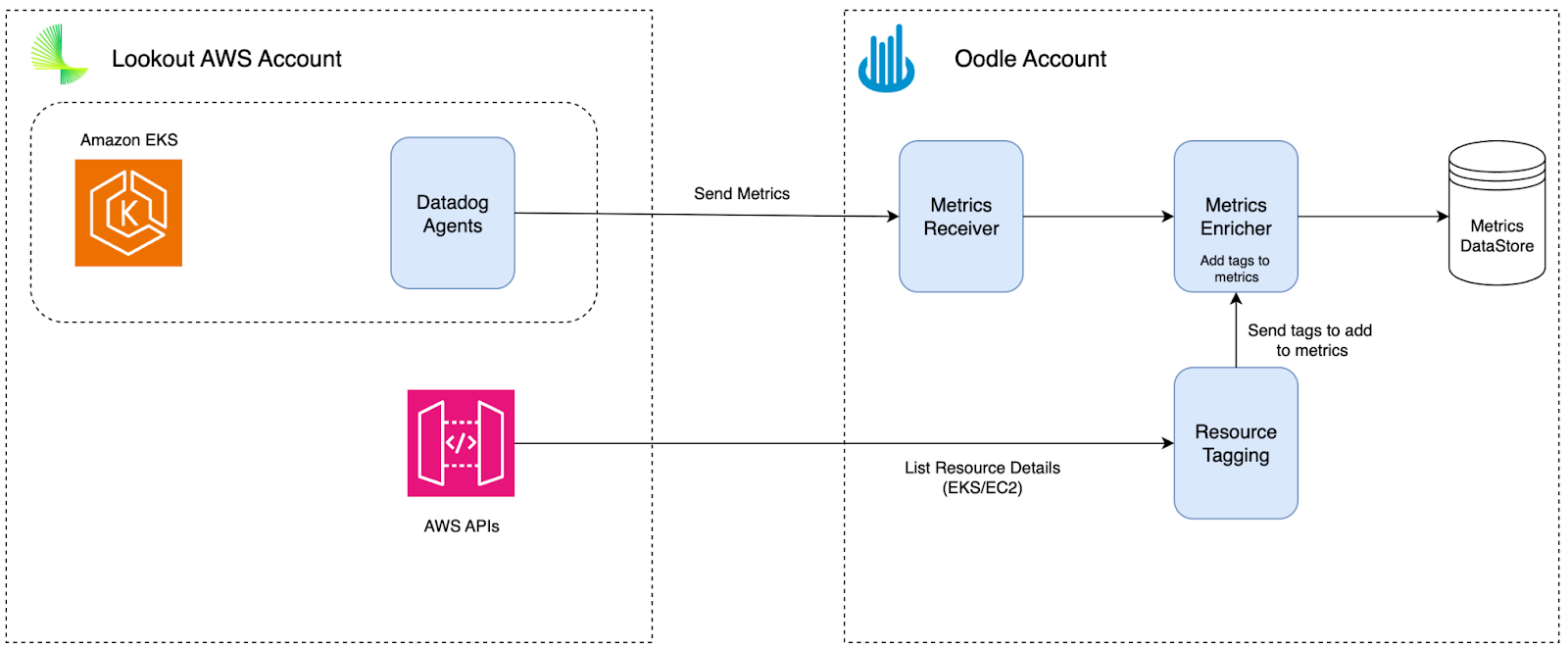
Here's what makes this tricky. Datadog's host-centric model attaches host tags to your metrics. Say you emit a custom metric api.latency from a host tagged with env:production and service:payments. Datadog enriches that metric with those tags automatically. You can filter and aggregate api.latency by environment or service even though you never added those tags to the metric itself. This is what makes Datadog's model powerful. It's also what many vendors fail to replicate.
What Lookout validated:
- Infrastructure metrics enriched with host tags
- Custom metrics enriched with host tags
- Cloud provider metrics enriched with resource tags (EC2 tags, GCP labels)
- Datadog checks supported natively
Visualization Validation
If you already know Grafana and OpenSearch, you'll feel right at home. If not, here's the honest truth: Datadog's visualizations are genuinely good. Expect some differences as you adjust to the Grafana and OpenSearch UX. That said, Oodle has made custom modifications to both to bring over Datadog features that customers care about, so you're not losing the good stuff, just getting it in a different wrapper.
Lookout's approach was pragmatic. Instead of demanding pixel-perfect widget matching, they asked: "What's the equivalent visualization that gives us the same insight?"
Challenges Every Datadog Migration Faces
During the PoC and migration, Lookout ran into a few challenges that come up in any Datadog migration evaluation. How these got resolved shaped their confidence in the move.
The Rollup Problem
This one is subtle but it trips up almost every migration. When you view a chart, the platform can't plot every raw data point. It aggregates them into time buckets. Datadog dynamically picks the bucket size based on chart type and time range (documented here).
Here's a real example. All three charts below show the same metric (kubernetes.pods.running summed by host), the same data, and the same 6-hour time range. Look at 17:40:
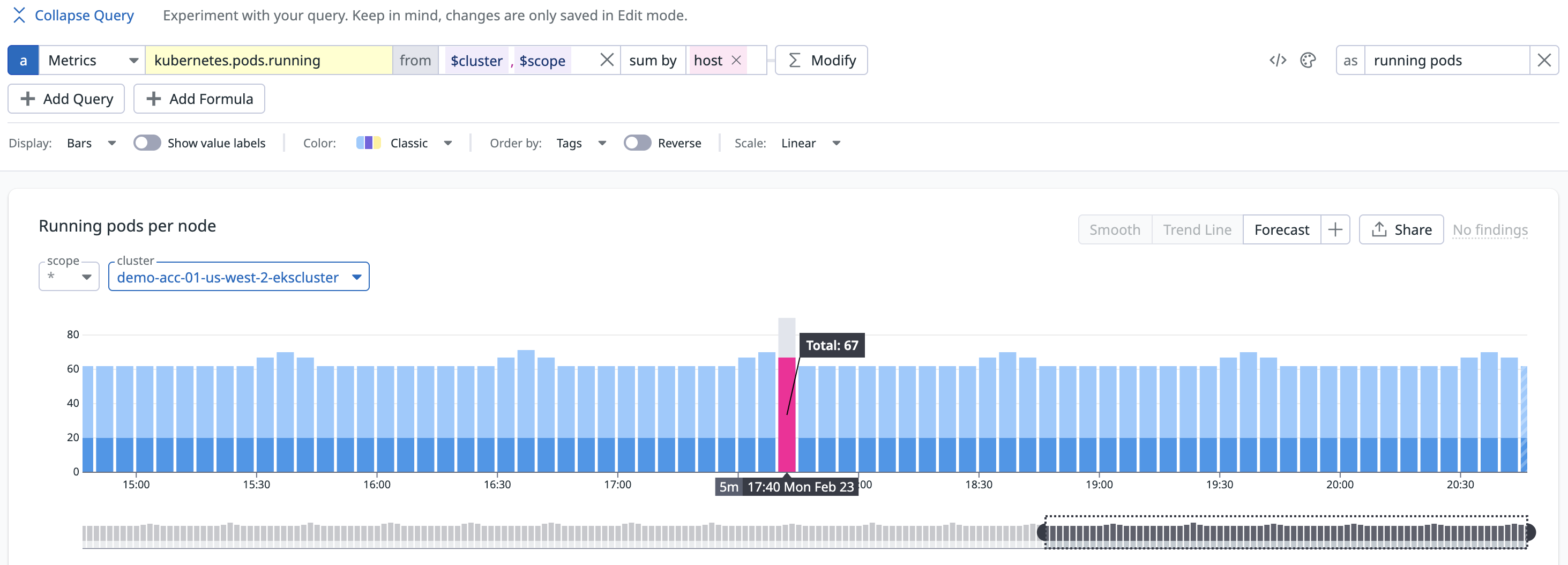
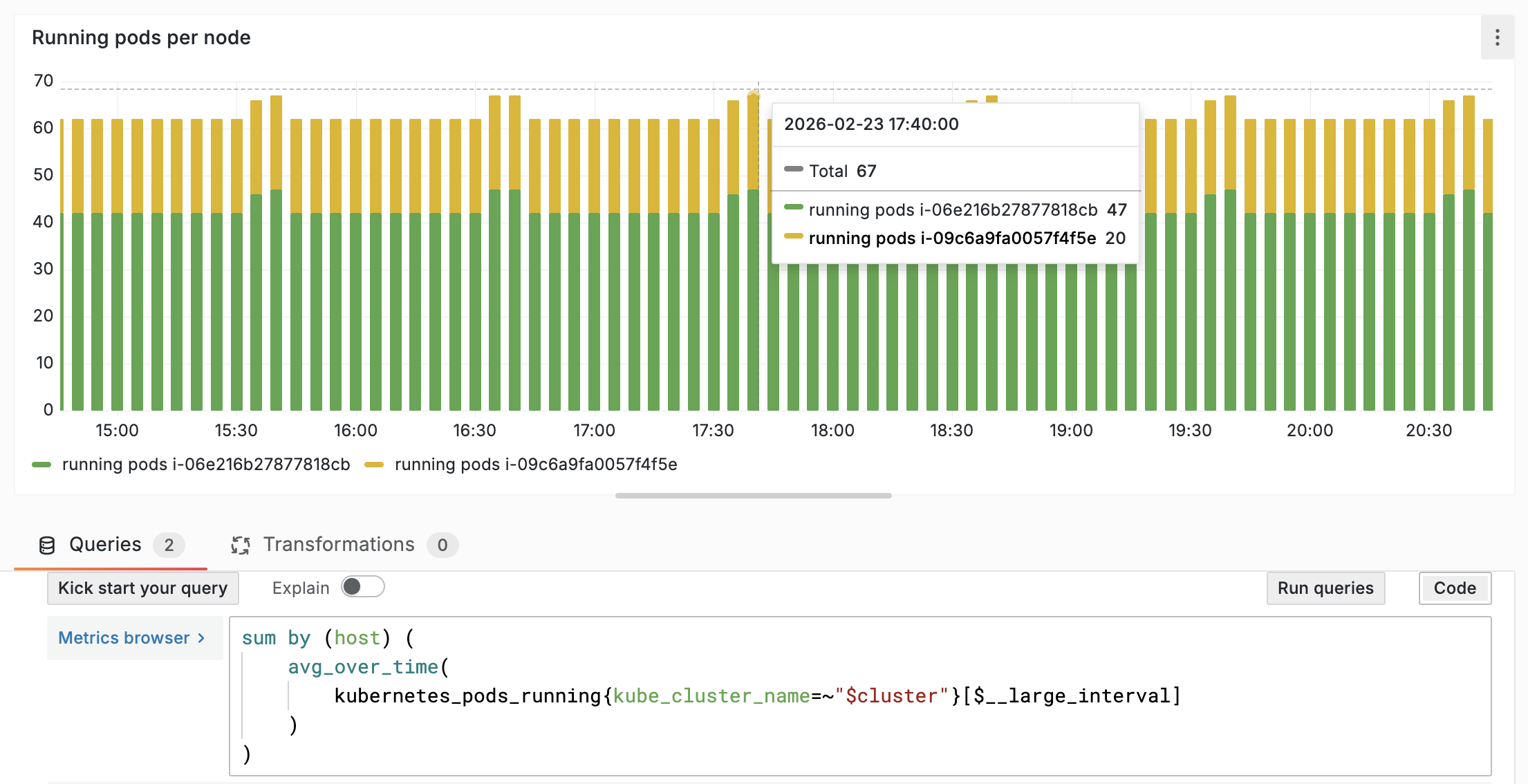
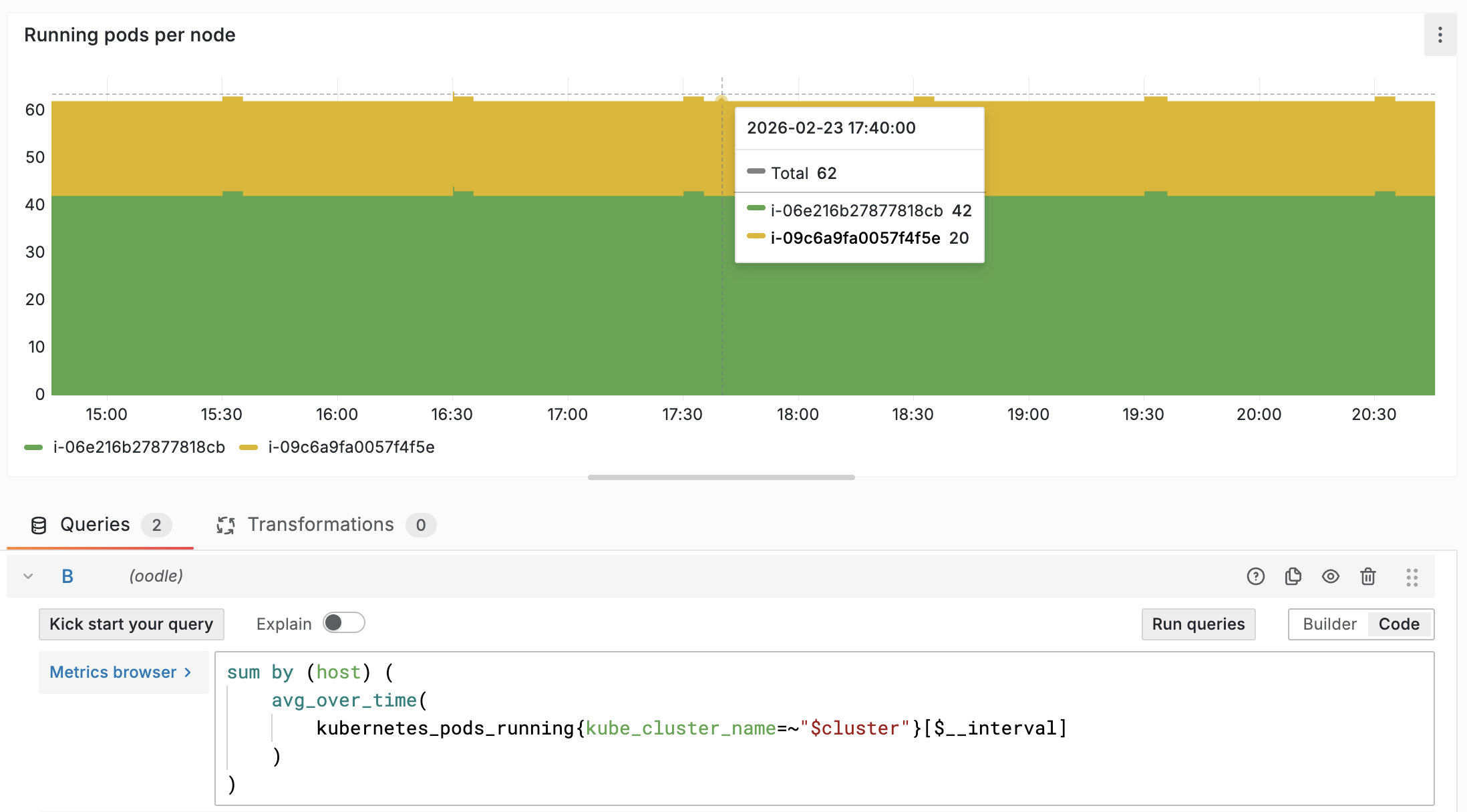
Same data. Same query. Same time range. A difference of 5 pods at a single point in time. Now multiply that kind of mismatch across hundreds of dashboards during a migration evaluation. Engineers see mismatched values and lose confidence because they can't tell whether a difference is a rollup mismatch or an actual data issue — even though nothing is wrong with the data itself.
How Oodle handles this: Oodle introduced custom interval variables in PromQL that match Datadog's rollup logic. The numbers you see in Oodle match Datadog. Not approximately, but exactly.
Most vendors wave this away as "different rollup implementation." Oodle took the harder path of matching Datadog's behavior so validation is straightforward.
Cloud Metric Ingestion: Stream vs. Pull
There are two models for pulling cloud metrics (e.g., from AWS):
- Metric Stream (push): Near real-time, but more expensive
- Metric Pull (pull): Better cost control, 5-10 minute delay
Both Datadog and Oodle default to Metric Pull. Oodle also supports tag-based filtering, so you can set up the integration to only pull metrics for production clusters (e.g., env: production), so you're not paying to ingest data you'll never look at.
Closing Integration Gaps
Oodle has a large list of integrations, but it doesn't cover everything Datadog offers. That's the honest trade-off. What matters is how fast gaps get closed when an integration matters to your workflows.
For Lookout, Jenkins monitoring and process monitoring were both critical. Neither existed in Oodle at the start of the evaluation. Oodle built Jenkins monitoring during the PoC, ingesting data from Datadog's agent and creating a visualization layer that matched Datadog's experience. Process monitoring followed shortly after.
"You guys just built the integrations we needed. My team was really impressed. They liked that."
— Beatrice Gelman, Senior Manager, Lookout
You're working with a vendor that doesn't have everything out of the box, but one that moves fast to fill the gaps that matter to you.
Production Migration: A 6-Week Collaborative Journey
"The fact that we achieved a full migration at our size in six weeks, I'm thrilled. I told my friends, yeah, we got it done in six weeks. They were like, what?"
— Beatrice Gelman, Senior Manager, Lookout
After a successful PoC, Lookout moved to full migration. The migration unfolded over six weeks of coordinated effort across platform, observability, and service teams. Rather than flipping a switch, it was a structured program with clear phases and shared ownership.
Scale
- 3,500 nodes to migrate
- 300+ dashboards to translate
- 2,000 monitors/alerts to recreate
- Timeline: 6 weeks
How the Rollout Unfolded
- Dual write. Send data from all the nodes to Datadog and Oodle.
- Translation. Migrate dashboards and monitors at scale.
- Gap closure. Fix missing workflows and integration gaps.
- Cutover. Unmute alerts gradually. Validate on call behavior. Deprecate dual
shipping and send all the data only to Oodle.
Who Owned What
| Task | Oodle Responsibility | Customer Responsibility |
|---|---|---|
| Dashboard translation | Automated migration + AI cleanup | Visual verification of data correctness + Fixes if required |
| Alert migration | Automated migration + AI cleanup | Verify sample of firing monitors |
| Notifier mapping | Notification configuration migration | Provide mapping to notification channels |
| Data verification | Statistical verification scripts | Manual spot-checking |
| Issue resolution | Continuous fix of reported issues | Report issues as discovered |
| Coordination | Dedicated engineers | One tech champion + representation from each team |
Dashboard Migration
Oodle's automated migration tool achieves 95-99% accuracy across dashboards. A key reason this accuracy is possible is that Oodle ingests directly from Datadog agents: the metric names follow a predictable Datadog-to-Prometheus naming convention (e.g., api.latency becomes api_latency). The translation is deterministic and well-defined. With vendors that require non-Datadog agents (e.g., OpenTelemetry), metric names and structures can change in less predictable ways during collection, meaning dashboard migration has to account for both query translation and metric remapping—a much harder problem.
Here's how the migration tooling works:
- Deterministic schema mapping: Handles the bulk of the translation
- AI validation and cleanup: Catches edge cases that automation misses
- Human QA: Verifies the final result
This layered approach matters because Datadog has a large set of widget types, not all of which have direct equivalents in Grafana. AI-only translations look great in demos but struggle at production scale — hallucinations, incorrect query translations, and subtle logic errors add up fast.
Here are the list of widget types and their support in Oodle:
| Widget Type | Support | Widget Type | Support |
|---|---|---|---|
| Timeseries | ✅ | List Stream | ✅ |
| Query Value | ✅ | Event Timeline | ✅ |
| Top List | ✅ | Manage Status | 🚧 In Progress |
| Query Table | ✅ | Hostmap | 🚧 In Progress |
| Note | ✅ | Image | ❌ |
| Bar Chart | ✅ | Distribution | 🚧 In Progress |
| Treemap | ✅ | SLO | ❌ |
| Alert Graph | ✅ | Change | ❌ |
| Heatmap | ✅ | Split Group | 🚧 In Progress |
| Check Status | ✅ | Event Stream | ❌ |
| Sunburst | ✅ | Powerpack | ❌ |
| Free Text | ✅ | SLO List | ❌ |
"Having you guys handle the migration and apply fixes holistically whenever we had an issue was a massive timesaver. If we had to do it by hand, I think we'd still be at it."
— Beatrice Gelman, Senior Manager, Lookout
Oodle tracked every dashboard and alert through a shared migration tracker, so both teams had full visibility into what was done, what needed fixes, and what was still in progress.
"Anything we uncovered, Oodle jumped on it. Some fixes were immediate, some had to be built custom for us, but it was a very good experience."
— Francisco J. Reyes, Lookout
Alert Migration
Alerts are where migrations tend to hurt the most. With over 2,000
alerts to move, Lookout had to be sure that every critical use case
would carry over. Here's what gets translated and what Oodle supports.
Alert structure:
- Query → Translated to PromQL
- Conditions → Mapped to critical/warning thresholds
- Message templates → Parsed and converted from Datadog's custom variable language
- Notification routing → Mapped to Oodle notifiers
Alert type support:
| Alert Type | Support |
|---|---|
| Query Alert | ✅ |
| Metric Alert | ✅ |
| Composite | ✅ |
| Service Check | ✅ |
| Event-v2 Alert | ❌ |
| Synthetics Alert | ❌ |
Resource Requirements
What does a 6-week migration actually cost in people-hours?
From Oodle:
- Dedicated engineers with deep Datadog knowledge
- Direct Slack channel (no customer success middleman)
- Continuous iteration on migration tooling based on your feedback
- Ownership of all dashboard/alert translation and QA
From the customer:
- Three engineers for coordination, config changes, and feedback
- One representative from each team to verify their own dashboards and alerts
- Final sign-off on migrated assets
What Made the Difference
The most important factor wasn't technical. It was how the two teams worked together. Lookout worked directly through a dedicated Slack channel with Oodle engineers who understood Datadog's internals, could make product changes during the migration, and responded to issues in real-time. No customer success relay. Beyond async communication, Oodle ran daily office hours during the migration where Lookout engineers could ask questions, share feedback, and get familiar with the product.
"I'm blown away by the approachability, the turnaround time, and being completely open to feedback. Everyone, hands down, is like, wow."
— Beatrice Gelman, Senior Manager, Lookout
"I told everyone, report your issues, these guys are quick to turn around. After the first week, everyone's like, wow, you weren't kidding."
— Beatrice Gelman, Senior Manager, Lookout
8 Years of Datadog, 6 Weeks to Migrate
Lookout proved that migrating from Datadog after 8 years is possible — even with 3,500 nodes, thousands of alerts and hundreds of dashboards. It took six weeks of collaborative work, not a magic button. And on the other side, they found more than just savings. They found a modern observability partner whose AI-native direction aligns with where their engineering org is heading. The question for most teams is not whether a move like this can be done. It is whether you want to keep absorbing the cost, or find a partner that fits where you are going and act on it.
For a broader architecture, pricing, and feature comparison, see Why Switch from Datadog. To assess your migration path, contact us or schedule a demo.